
Se llama igual que el popular tabernero de Los Simpson, pero MoE no es un personaje de dibujos animados, sino el acrónimo de Mixture of Experts (mezcla de expertos), una arquitectura que mejora la eficiencia del procesamiento de la inteligencia artificial. La compañía Oppo se ha convertido en la primera del mundo que implementa esta tecnología en sus dispositivos móviles, abriendo nuevas posibilidades para una IA más avanzada y flexible en los smartphones y sentando las bases para futuras innovaciones en este sector.
Los modelos modernos de deep learning (aprendizaje profundo) se construyen a partir de redes neuronales artificiales, que comprenden varias capas de nodos interconectados (o «neuronas»). Cada neurona tiene una función de activación: una operación matemática realizada sobre los datos recibidos de la capa anterior.
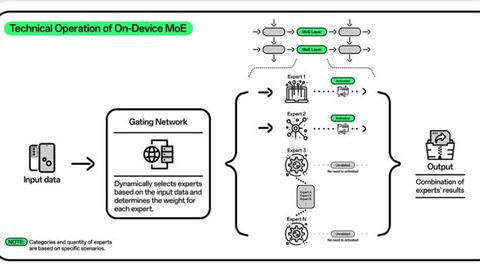
MoE permite que los modelos a gran escala, incluso los que comprenden muchos miles de millones de parámetros, reduzcan en gran medida los costes de cálculo durante el preentrenamiento y logren un rendimiento más rápido. En términos generales, logra esta eficiencia mediante la activación selectiva solo de los «expertos» específicos necesarios para una tarea determinada, en lugar de activar toda la red neuronal para cada tarea.
Según explica Dave Bergmann, de IBM, a medida que los principales modelos de deep learning utilizados para la IA generativa se han vuelto cada vez más grandes y exigentes a nivel de hardware, la mezcla de expertos ofrece un medio para abordar el equilibrio entre la mayor capacidad de los modelos más grandes y la mayor eficiencia de los modelos más pequeños. «Esto se ha explorado sobre todo en el campo del procesamiento del lenguaje natural (PNL): algunos de los principales modelos de lenguaje de gran tamaño (LLM), como el Mixtral 8x7B de Mistral y el GPT-4,2 de OpenAI, han empleado la arquitectura MoE», señala Bergmann.
Las pruebas de laboratorio realizadas por Oppo revelan que la arquitectura MoE en los dispositivos móviles acelera la velocidad de las tareas de IA en aproximadamente un 40 %, lo que reduce la demanda de recursos y mejora la eficiencia energética. Esto se traducirá en respuestas de IA más rápidas y mayor duración de la batería.